Kotlin 의 람다 Lambda
- Part.1 람다 식
- Part.1 멤버 참조
- Part.1 함수형 스타일
- Part.2 시퀀스
Sequence: 지연 컬렉션 연산 - Part.2 자바 함수형 인터페이스 코틀린에서 사용
- Part.2 수신 객체 지정 람다 사용
지연 계산(lazy) 컬렉션 연산
코틀린의 ‘Sequence’
코틀린의 함수형 API들은 연산 과정에서 생성되는 새로운 중간 컬렉션을 즉시 생성한다. 그런 경우 중간 결과 객체가 많아지면서 메모리 이슈가 발생하고 성능 저하와 같은 장애가 발생할 수 있다. 코틀린에서는 이런 장애를 방지하기 위해 컬렉션 연산을 지연 계산할 수 있는 시퀀스 sequence API를 제공한다.
먼저 왜 중간 결과 객체가 장애를 발생할 수 있는지 살펴보겠다.
// `people` 컬렉션의 `Person` 클래스의 `name` 중 "A" 로 시작하는 원소 찾는다.
people
.map(Person::name)
.filter { it.startWith("A") }위 코드의 문제점은 people 리스트의 모든 원소를 .map() 반복하면서 새로운 String 객체를 리스트의 사이즈만큼 다시 생성한다.
이런 코드는 수백만 개의 리스트 컬렉션을 처리할 때 문제가 발생할 수 있다. 그렇다면, 시퀀스 sequence 는 어떤 처리를 하는 것일까?
people
.asSequence()
.map(Person::name)
.filter { it.startWith("A") }시퀀스 API 는 일반 컬렉션의 함수형 API를 그대로 구현하고 똑같이 활용 가능하지만, 큰 차이점은 바로 중간 결과 객체를 생성하지 않는다.
과연 “중간 결과 객체를 생성하지 않는다.” 라는 의미는 무엇일까?
시퀀스 연산 실행: 중간 연산과 최종 연산
시퀀스 에 대해 제대로 이해하기 전에, 먼저 중간intermediate 연산 과 최종termainal 연산 에 대한 이해를 먼저 필요하다.
중간 연산
중간 연산 은 연산은 통한 다른 시퀀스를 반환하게 되고, 최초 시퀀스의 원소를 반환하는 방법을 알고 있다. 그리고, 항상 지연 계산 된다.
listOf(1, 2, 3, 4)
.asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }위 코드를 실행하면 print() 내용은 출력되지 않는다. .map() 과 .filter() 변환이 늦춰지면서 결과를 얻을 필요가 있을 때, 연산이 적용되면서 최종 결과를 계산하고 반환하게 된다.
최종 연산
최종 연산 은 말그대로 연산에 대한 결과를 반환한다. 최종 연산을 호출하면 연기됐던 모든 계산을 수행한다.
listOf(1, 2, 3, 4)
.asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }
.toList()코틀린의 시퀀스를 활용하면, 지연 계산으로 중간 객체 생성없이 계산된 결과를 반환할 수 있다.
지연 계산
일반 컬렉션에서 즉시 계산 방식은 매번 연산에 대한 결과 중간 컬렉션이 생성이 된다.
listOf(1, 2, 3, 4) // list1 = [1, 2, 3, 4]
.map { it * it } // list2 = [1, 4, 9, 16]
.filter { it % 2 == 0 } // list3 = [4, 16]즉시 계산은 위와 같이 하나의 컬렉션에 대한 연산 처리를 위해 총 3개의 컬렉션이 생기게 된다.
지연 계산 은 새로운 중간 컬렉션 객체를 생성하지 않고, 모든 연산이 각 원소에 대해 순차적으로 적용된다.
listOf(1, 2, 3, 4)
.asSequence()
.map { it * it }
.find { it % 2 == 0 }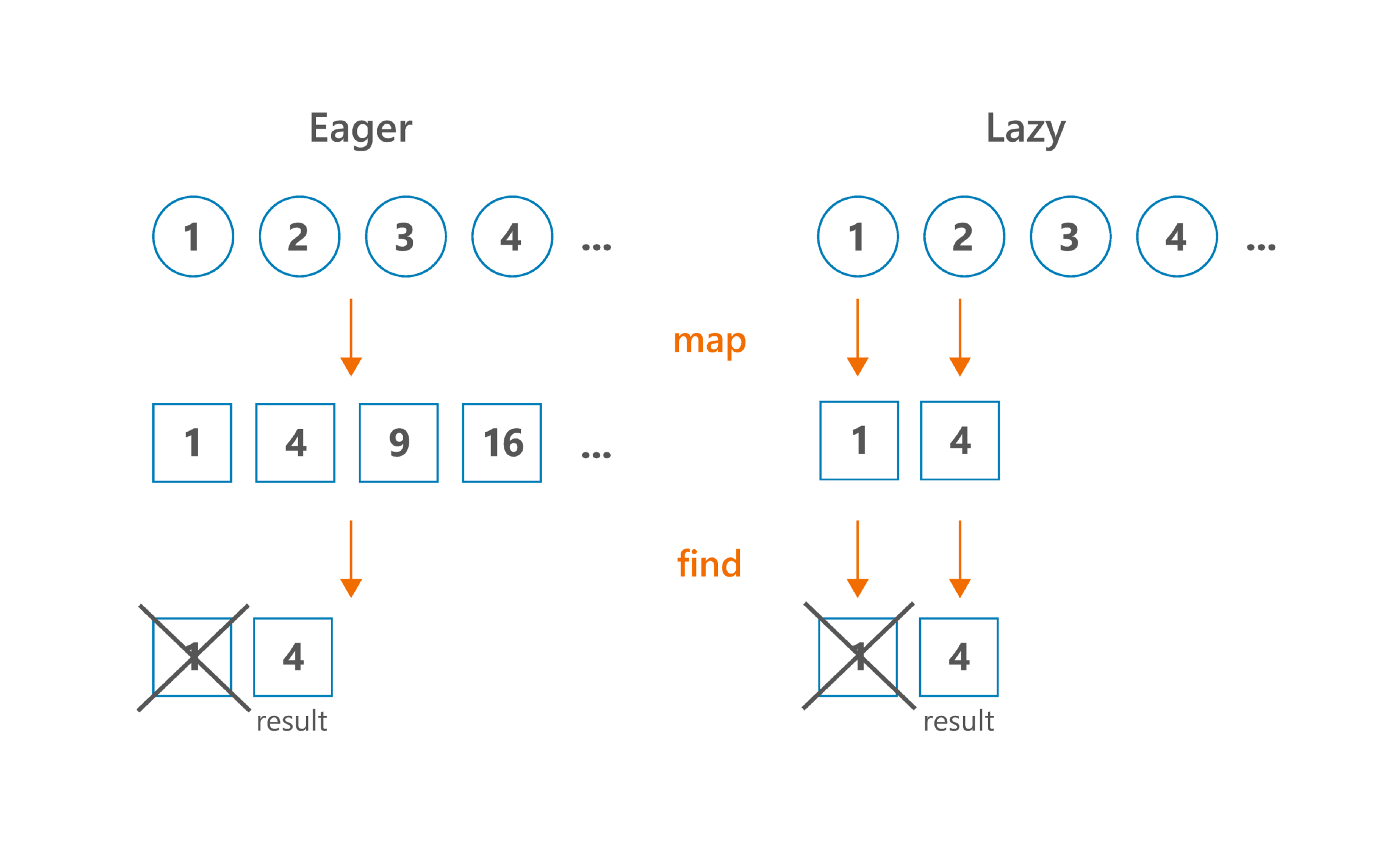
위 그림처럼 즉시 계산(왼쪽) 방식은 컬렉션의 크기만큼(또는 연산된 컬렉션 크기만큼) 새로운 객체를 생성하지안, 지연 계산(오른쪽) 방식은 각 원소에 대한 연산 처리 후 반환하게 된다. 그러면 .find() 로 찾은 4 라는 결과값이 있으니 더이상 나머지 컬렉션에 대한 원소를 연산하지 않는다.
시퀀스 의 지연 계산은 이런 방식을 통해 프로그램의 OOM 이나 메모리 이슈를 방지할 수 있는 안전 장치 역할을 하게 된다.
컬렉션 연산 순서로 성능 개선 방법
val people = listOf(Person("KIM", 29), Person(JIM, 33))
.map(Person::age)
.filter { it > 30 }위 코드는 모든 원소에 대한 .map() 을 적용하고 .filter() 를 통해 조건을 적용하게 된다. 이렇게 되면 최초 컬렉션의 크기만큼 중간 컬렉션이 생성되지만, 아래와 같은 코드는 그렇지않다.
val people = listOf(Person("KIM", 29), Person(JIM, 33))
.asSequence()
.filter { it.age > 30 }
.map(Person::age)위 코드는 시퀀스와 연산의 순서를 .filter() 부터 적용하고, .map() 을 적용하였다.
이런 순서라면, 먼저 조건에 부합된 원소만 남겨지고 .map() 의 함수가 적용되니 훨씬 연산 수가 줄어들게 된다.
이와 같이 코틀린에서는 시퀀스 와 컬렉션 람다 함수의 연산 순서에 따라 성능 개선을 손쉽게 할 수 있는 장점이 있다.
자바 함수형 인터페이스 코틀린에서 사용
코틀린의 람다는 다향한 코드를 공통화하여 가독성과 코드의 유지보수성을 높일 수 있다. 하지만 코틀린이 자바 기반으로 나온 프로그래밍의 언어이고, 자바와 계속 상호 운용할 수 있는 언어가 되기 위해서, 코틀린은 자바에서도 코틀린의 람다를 활용할 수 있도록 지원하고 있다.
button.setOnClickListener { view -> ... }위와 같은 코틀린의 람다를 활용하는 .setOnClickListener() 함수를 자바에서는 아래와 같이 활용할 수 있다.
public interface OnClickListener {
void onClick(View view);
}자바는 함수형 인터페이스 또는 SAM 인터페이스 라고 추상 메소드가 단 하나만 있는 인터페이스을 통해 코틀린의 람다를 활용할 수 있다.
SAM 생성자
SAM Sigle Abstract Method 은 단일 추상 메소드란 의미로, 자바 API 중에는 Runnable 이나 Callable 과 같은 함수형 인터페이스를 제공하는 역할을 한다. SAM 생성자 는 람다를 함수형 인터페이스의 인스턴스로 변환할 수 있게 컴파일러가 자동으로 생성하는 함수다.
수신 객체 지정 람다 사용
수신 객체 지정 람다 는 수신 객체를 명시하지 않고, 람다의 본문 안에서 다른 객체의 메소드를 호출할 수 있게 한다.
with 함수
어떤 객체의 이름을 반복하지 않고도 그 객체에 대해 다양한 연산을 수행할 수 있다.
fun alphabet() = with(StringBuilder()) {
for (letter in 'A'..'Z') {
append(letter)
}
toString()
}with 함수는 첫 번째 인자로 받은 객체를, 두 번째 인자로 받은 람다의 수신 객체로 만든다.
apply 함수
apply 는 with 함수와 거의 비슷하지만, 항상 자신에게 전달된 객체를 반환한다.
fun alphabat() = StringBuilder().apply {
for (letter in 'A'...'Z') {
append(letter)
}
}.toString()apply 함수는 확장 함수로 정의되어 있고, 수신 객체가 전달받은 람다의 수신 객체가 된다. 실행 결과 반환되는 타입은 수신 객체의 타입이된다.
apply 함수는 객체의 인스턴스를 만들면서 즉시 프로퍼티 중 일부를 초기화하는 경우 유용하다.
val person = Person("JIM").apply {
age = 33
}{kind=link}