Elasticsearch 시작하기
Elasticsearch 의 기본 설치 및 설정 방법을 살펴보자.
- 데이터 색인
- Elasticsearch 설치 방법 (링크 첨부)
- Elasticsearch 환경 설정
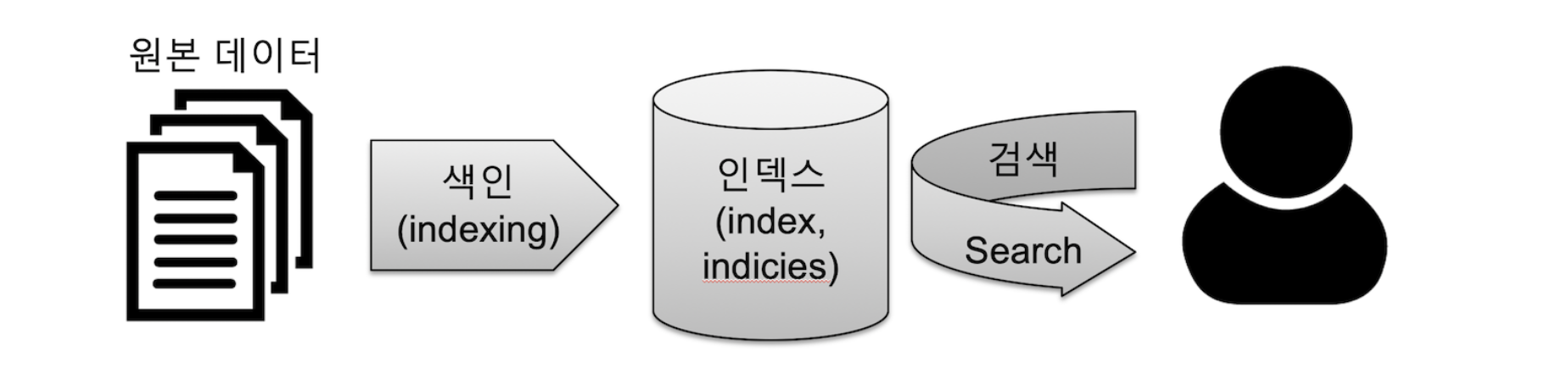
데이터 색인
검색 기술을 보다보면 색인 (Indexing) 이란 단어가 많이 나오게 된다. 색인 과 관련된 용어 정리를 하고 넘어가자.
| 용어 | 명칭 | 설명 |
|---|---|---|
| Indexing | 색인 | 데이터가 검색될 수 있는 구조로 변경하기 위해 데이터 원본 문서를 검색어 토큰으로 변환하여 저장하는 과정이다. |
| Index, Indices | 인덱스 | 색인 과정을 거친 결과물, 또는 결과물이 저장되는 저장소를 의미한다.Elasticsearch 에서는 Document 들의 논리적인 집합으로 표현되는 단위이기도 하다. |
| Search | 검색 | Index 에 들어있는 검색어 토큰을 포함하고 있는 Document 를 찾아가는 과정이다. |
| Query | 질의 | 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어 또는 검색 조건을 의미한다. |
Elasticsearch 설치 방법
설치 방법에 대해서는 정확한 가이드북을 참고하는 것이 좋을 것 같아 정리 대신 링크 첨부로 대신한다.
AWS EC2 + Elasticsearch 환경 구축을 위해 별로 내용을 정리하였다.
Elasticsearch 환경 설정
대용량 데이터 처리를 위해서 Elasticsearch 도 분산 클러스터을 구성할 수 있다.
클러스터 설정을 위한 간략한 환경 설정 방식을 살펴보고자 한다.
Elasticsearch 설정 항목
jvm.options: Java Heap 메모리 및 환경 변수 설정elasticsearch.yml:Elasticsearch옵션 설정log4j2.properties: LOG 관련 옵션 설정
jvm.options
Elasticsearch 는 JVM 위에서 동작하게 되고, 7.0 기준 1GB 의 Heap 메모리가 기본으로 설정되어 있지만,
아래와 같은 옵션으로 설정을 변경할 수 있다.
Xms1gXmx1g
이 외에도 Java 와 같은 환경 변수을 활용하여 다른 설정이 가능하다.
elasticsearch.yml
Elasticsearch 실행에 대한 실제 설정은 elasticsearch.yml 에서 이루어진다.
설정 항목
| 항목 | 설명 |
|---|---|
cluster.name: "<클러스터명>" |
클러스터 이름을 설정한다. Elasticsearch 의 노드들은 클러스터명이 같으면 같은 클러스터로 묶이고,클러스터명이 다르면 동일한 물리적 장비나 바인딩이 가능한 네트워크상에 있더라도 서로 다른 클러스터로 바인딩이 된다. (default : "elasticsearch") |
node.name: "<노드명>" |
실행 중인 각각의 Elasticsearch 노드들을 구분할 수 있는 노드의 이름을 설정한다.설정하지 않으면 7.0 버전부터는 호스트명, 6.X 이하 버전은 프로세스 UUID 의 첫 7글자가 노드명으로 설정된다. |
node.attr.<key>: "<value>" |
노드별로 속성을 부여하기 위한 일종의 네임스페이스를 지정한다. hot / warm 아키텍처를 구성하거나 물리 장비 구성에 따라 샤드 배치를 임의적으로 조절하는 등의 설정이 가능하다. |
path.data: ["<경로>"] |
색인된 데이터를 저장하는 경로를 지정한다. 기본 경로는 Elasticsearch 가 설치된 홈 ~/ 경로 아래의 ~/data 디렉토리이다. |
path.logs: "<경로>" |
Elasticsearch 실행 로그를 저장하는 경로를 지정한다.기본 경로는 ~/logs 디렉토리이다. |
bootstrap.memory_lock: true |
Elasticsearch 가 사용 중인 힙 메모리 영역을 다른 Java 프로그램이 간섭 못하도록 미리 접유하는 설정이다.항상 true 로 설정하는 것을 권장한다. |
network.host: <IP 주소> |
Elasticsearch 가 실행되는 서버의 IP 주소를 설정한다.(default: 127.0.0.1)해당 설정이 주석 및 루프백인 경우, 개발 모드로 실행된다. 실제 IP 주소로 설정되면 운영 모드로 실행되며,노드를 시작할 때 부트스트랩 체크를 한다. 서버의 내/외부 주소 모두 지정 가능하고, 추가적인 설정을 이용하여 구분하여 지정해야 한다. - network.bind_host : 내부망- network.publish_host : 외부망그리고 해당 설정에서 사용되는 특별한 변수값이 있다. - _local_ : 루프백 주소 127.0.0.1 설정- _site_ : 로컬 네트워크 주소 설정- _global_ : 네트워크 외부에서 바라보는 주소 설정 |
http.port: <Port 번호> |
Elasticsearch 와 클라이언트가 통신하기 위한 HTTP Port 를 설정한다.(default: 9200)이미 Port 가 사용 중인 경우 9200 ~ 9299 사이의 값으로 차례대로 설정된다. |
transport.port: <Port 번호> |
Elasticsearch 노드끼리 서로 통신하기 위한 TCP Port 를 설정한다.(default: 9300)이미 Port 가 사용 중인 경우 9300 ~ 9399 사이의 값으로 차례대로 설정된다. |
discovery.seed_hosts:[ "<호스트-1>", "<호스트-2>", ... ] |
클러스터 구성을 위해 바인딩 할 원격 노드의 IP 또는 도메인 주소를 배열 형태로 입력한다. 해당 설정은 7.0 버전부터 지원하고, 6.X 이하 버전은 discovery.zen.ping.unicast.hosts 으로 zen 디스커버리 설정을 할 수 있다. |
cluster.initial_master_nodes:[ "<노드-1>", "<노드-2>" ] |
클러스터가 최초 실행 될 때 명시된 노드들을 대상으로 마스터 노드를 선출한다. 해당 설정은 7.0 버전부터 지원하고, 6.X 이하 버전은 discovery.zen.minimum_master_nodes 으로 마스터 노드 후보의 크기를 설정을 할 수 있다. |
Node 역할 분류
Elasticsearch 의 노드는 여러 가지의 역할을 분담하여 수행하고 있다. elasticsearch.yml 에서 간단하게 노드의 역하을 설정할 수 있다.
| 항목 | 설명 |
|---|---|
node.master: true |
마스터 후보 노드를 설정한다. 모든 클러스터는 1개 마스터 노드가 존재하며, 마스터 노드에 장애가 발생한 경우, 다른 마스터 후보 노드 중에서 마스터 노드를 선출한다. |
node.data: true |
해당 노드가 데이터를 저장할 수 있도록 설정한다. |
node.ingest: true |
데이터 색인시 전처리 작업인 Ingest Pipline 작업 수행 가능한지 설정한다. |
node.ml: true |
머신러닝 작업을 수행 가능한지 설정한다. |
해당 노드 설정을 모드
false로 하는 경우도 있다. 이런 경우는 오로지 클라이언트와 통신만 하는 노드로 사용된다.
이런 노드를Coordinate only Node라고 부른다.
- 위 설정들은
elasticsearch.yml뿐 아니라Command Line커맨드 명령을 통해서 설정 가능하다. -E <옵션>=<값>와 같이Elasticsearch실행할 때 입력하면 환경 설정이 가능하다.
# 아래와 같이 설정된 옵션은 커맨드 명령을 통해 설정된 옵션이 우선적으로 설정된다.
$ bin/elasticsearch -E cluster.name=my-cluster -E node.name="node-1"{kind=link}