데이터 색인과 텍스트 분석 Part.1
Elasticsearch 에서 최적화 검색을 위해 데이터 원본 문서를 Inverted Index 역인덱스 과정을 거친다.
역인덱스 과정은 텍스트 분석을 하는 애널라이저를 통해서 이뤄지며, 검색 최적화를 위해 Elasticsearch 에서는
다양한 설정을 지원하고, 처리 가능하다.
Elasticsearch 의 역인덱스 과정을 이해하기 위해서는 다음과 같은 개념들이 필요하다.
Inverted Index- 역인덱스Text Analysis- 텍스트 분석Analyzer- 애널라이저Character Filter- 캐릭터 필터Tokenizer- 토크나이저Token Filter- 토큰 필터
Stemming- 형태소 분석
Inverted Index 역인덱스
Inverted Index역인덱스 는 주요 키워드가 어느 문서에 있는지 볼 수 있도록 분리하는 과정이라 할 수 있다.- 역인덱스 과정을 거쳐 나온 각 키워드를
Term텀 이라고 부른다.
원본 문서

역인덱스 결과
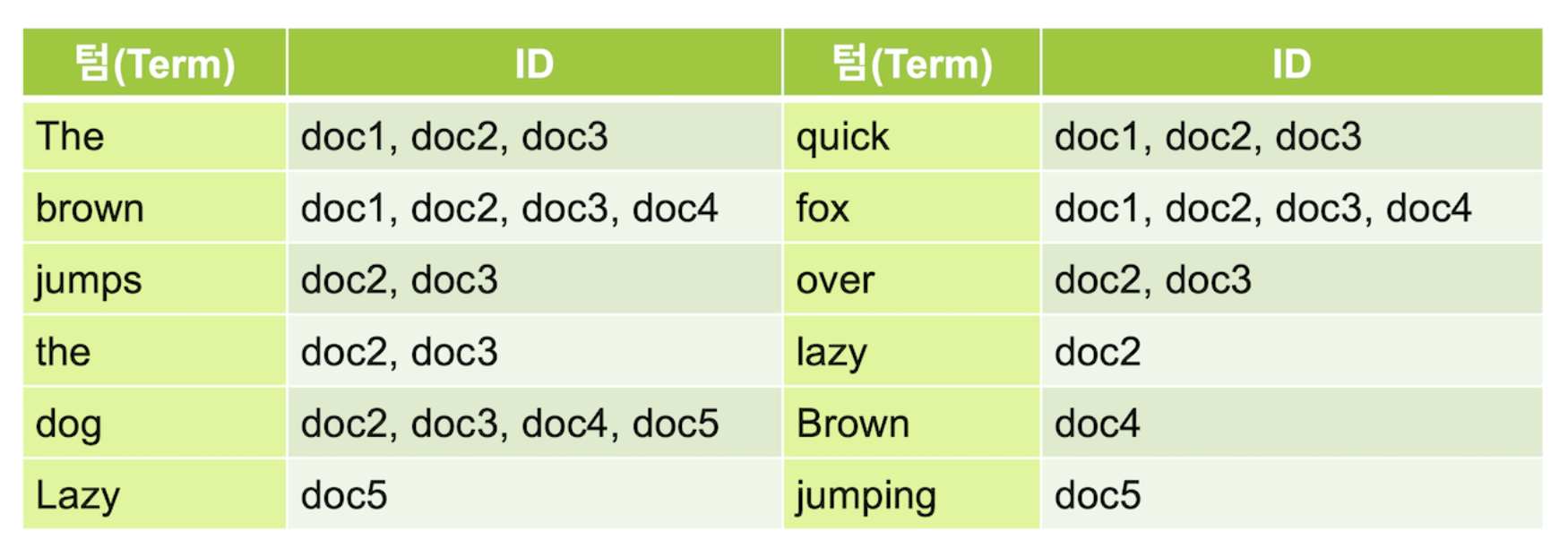
역인덱스 과정을 거쳐 생성된
Term은 역인덱스 검색 결과에 대해서만 관여한다.
원본 문서는 변하지 않기 때문에, 검색 결과는 항상 원본 문서를 그대로 확인할 수 있다.
Text Analysis 텍스트 분석
역인덱스 결과를 도출하기 위해 Text Analysis 텍스트 분석 이라는 전체적인 과정을 거친다.
텍스트 분석 이란 과정을 수행하는 기능을 Analyzer 애널라이저 라고 한다.
바로 애널라이저 에 대해 알아보자.
Analyzer 애널라이저
애널라이저 는 Character Filter 캐릭터 필터, Tokenizer 토크나이저, Token Filter 토큰 필터 로 구성된다.
| 구분 | 개수 | 설명 |
|---|---|---|
Character Filter |
0 ~ 3 개 |
특정 문자를 대치하거나 제거 처리 과정 수행 |
Tokenizer |
1 개 |
단어를 Term 텀 단위로 하나씩 분리 처리 과정 수행 |
Token Filter |
0 ~ N 개 |
분리된 Term 텀을 하나씩 가공 처리 과정 수행 |
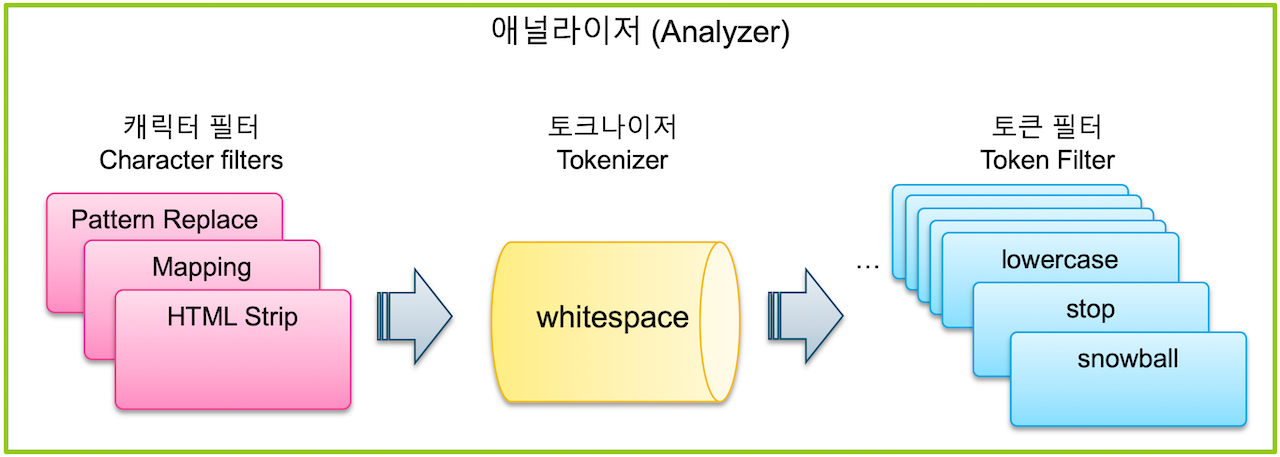
Character Filter 캐릭터 필터
Character Filter 캐릭터 필터는 텍스트 분석 과정에서 제일 처음으로 수행되는 과정으로,
색인된 텍스트가 토크나이저를 통해 Term 텀으로 분리되기 전에 전체 문장에 대해 일련의 작업이 적용되는 전처리 도구이다.
7.0 버전부터는 캐릭터 필터로 HTML Strip, Mapping, Pattern Replace 총 3개가 있다.
3개를 모두 차례대로 적용할 수도 있고, 사용자 지정을 통해 다르게 지정 가능하다
HTML Strip 필터
HTML Strip 필터는 색인된 파일에 HTML 텍스트인 경우, HTML 태그를 제거하여 일반 텍스트로 만든다.
<> 와 같은 태그를 포함하여 특수문자를 표현하는 HTML 문법도 해석하여 대치한다.
Request
POST _analyze
{
"tokenizer": "keyword",
"char_filter": [
"html_strip"
],
"text": "<p>I'm so <b>happy</b>!</p>"
}Response
{
"tokens" : [
{
"token" : """
I'm so happy!
""",
"start_offset" : 0,
"end_offset" : 32,
"type" : "word",
"position" : 0
}
]
}Mapping 필터
Mapping 필터는 지정한 단어를 다른 단어로 치환 가능하다.
특수문자 등을 포함한 검색 기능을 구현하는 경우 필수적으로 설정해야하는 필터라고 한다.
Mapping 필터 등록 방법
cpp_char_filter등록을 통해 필터 타입 지정mappings필드에서 치환하고자 하는 단어 지정
e.g. C++ 단어는 C_plus__plus_ 로 변형되어 저장된다.
PUT coding
{
"settings": {
"analysis": {
"analyzer": {
"coding_analyzer": {
"char_filter": [
"cpp_char_filter"
],
"tokenizer": "whitespace",
"filter": [ "lowercase", "stop", "snowball" ]
}
},
"char_filter": {
"cpp_char_filter": {
"type": "mapping",
"mappings": [ "+ => _plus_", "- => _minus_" ]
}
}
}
},
"mappings": {
"properties": {
"language": {
"type": "text",
"analyzer": "coding_analyzer"
}
}
}
}Pattern Replace 필터
Pattern Replace 필터는 정규식(Regular Expression)을 이용하여 단어를 치환해주는 필터이다.
Pattern Replace 필터 등록 방법
PUT camel
{
"settings": {
"analysis": {
"analyzer": {
"camel_analyzer": {
"char_filter": [
"camel_filter"
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
},
"char_filter": {
"camel_filter": {
"type": "pattern_replace",
"pattern": "(?<=\\p{Lower})(?=\\p{Upper})",
"replacement": " "
}
}
}
}
}Tokenizer 토크나이저
Elasticsearch 에서 텍스트 분석 과정 중 제일 큰 영향력이 있는 단계가 Tokenizer 토크나이저이다.
토크나이저는 입력된 데이터에 Term 텀으로 분리하는 과정을 수행한다.
토크나이저는 반드시 단 한개만 지정 가능하며, tokenizer 필드를 통해 설정한다.
주로 많이 사용되는 일반적인 토크나이저들은 다음과 같다.
Standard,Letter,WhitespaceUAX URL EmailPatternPath Hierarchy
Standard, Letter, Whitespace 토크나이저
Standard, Letter, Whitespace 토크나이저는 일반적으로 많이 사용하는 토크나이저들이지만, 비슷하면서도 다른 차이점을 가진다.
Standard: 공백을 기준으로Term텀을 분리하면서@과 같은 특수 문자를 제거한다.- 하지만, 문자열 중간에 있는 특수 문자는 제거되지 않는다. (
e.g. quick.brown_FOx와 같은 문자열의.,_는 중간에 있기 때문에 제거되지 않는다.)
- 하지만, 문자열 중간에 있는 특수 문자는 제거되지 않는다. (
Letter: 영어 알파벳을 제외한 모든 공백, 숫자를 기준으로 텀을 분리한다.Whitespace: 스페이스, 탭, 개행 같은 공백 문자만을 기준으로 텀을 분리한다.
Letter와Whitespace는 의도와 다르게 문자가 다양한게 분리될 수 있기 때문에 보통Standard토크나이저로 설정한다고 한다.
UAX URL Email 토크나이저
UAX URL Email 토크나이저는 Standard 토크나이저가 특수 문자까지 모두 제거하는 단점을 보완한다.
이를 통해 이메일 정보나 웹 URL 정보를 그대로 보존하여 텀을 분리할 수 있다.
Pattern 토크나이저
Pettern 토크나이저는 Java 정규식을 활용하여 텀을 분리한다.
공백을 기준으로 텀을 분리하는 다른 토크나이저와 달리 특정한 문자를 기준으로 분리해야하는 CSV 파일 같은 데이터를 분리할 수 있을 것 같다.
Path Hierarchy 토크나이저
Path Hierarchy 토크나이저는 디렉토리명 같이 계층 구조인 입력 데이터를 계층 구조에 맞게 텀을 분리한다.
예를 들어, /usr/share/elasticsearch/bin 이란 문자열을 Path Hierarchy 토크나이저로 분리하면 다음과 같다.
{
"tokens" : [
{
"token" : "/usr",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/share",
"start_offset" : 0,
"end_offset" : 10,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/share/elasticsearch",
"start_offset" : 0,
"end_offset" : 24,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/share/elasticsearch/bin",
"start_offset" : 0,
"end_offset" : 28,
"type" : "word",
"position" : 0
}
]
}문자열을 분리하는 기준인
delimiter도 다양하게 지정할 수 있지만,default : /이다.
delimiter기준으로 분리하지만, 저장할 때는 다른 문자로 저장하고자 한다면replacement필드로 지정할 수 있다.
Token Filter 토큰 필터
Token Filter 토큰 필터는 토크나이저 과정을 거쳐 분리된 텀을 일정한 규칙에 맞게 처리해주는 과정을 수행한다.
여러 개의 필터를 등록할 수 있고, 순서에 따라 처리 결과가 달라지기 때문에 순서에 유의하여 설정해야 한다.
토큰 필터도 동일하게 자주 사용되는 필터 위주로 살펴보겠다.
Lowercase,UppercaseStopSynonymNGram,Edge NGram,ShingleUnique
Lowercase, Uppercase 토큰 필터
Lowercase, Uppercase 토큰 필터는 영어로 입력된 데이터를 대소문자 상관없이 검색될 수 있도록
텀으로 분리된 정보를 모두 각각 소문자 또는 대문자로 변경 처리하는 토큰 필터이다.
Stop 토큰 필터
Stop 토큰 필터는 Stopword 불용어를 제거해주는 토큰 필터이다.
Elasticsearch 에서 지원해주는 언어팩을 활용하여 각 언어에 맞는 불용어를 제거할 수 있다.
언어팩 설정 외에도 특정한 불용어 목록을 불용어 단어 사전 파일 또는 직접 지정하여 설정 가능하다.
Synonym 토큰 필터
Synonym 토큰 필터는 동의어를 검색 요청하면 검색되어 동일한 결과를 보여줄 수 있도록 저장된 텀의 동의어 저장해주는 토큰 필터이다.
예시로, AWS 란 검색어에 대해서는 Amazon, 아마존 같은 다른 언어의 동의어도 함께 검색될 수 있도록 할 수 있다.
Synonym 토큰 필터도 직접 목록을 입력하여 설정할 수 있지만, 동의어 단어 사전 파일 생성하여 설정 가능하다.
NGram, Edge NGram, Shingle 토큰 필터
Elasticsearch 는 RDMS 에서 사용하는 LIKE 검색과 같은 다소 성능 저하되는 부분을 보완하기 위해서 NGram 토큰 필터를 지원한다.
NGram
unigram(1글자), bigram(2글자) 씩 단어를 분리하여 토큰을 저장한다.
house를bigram필터 적용하면,ho,ou,us,se로 분리된다.house를mix_gram: 2, max_gram: 3적용하면,ho,hou,ou,ous, … 분리된다.
NGram토큰 필터를 사용하면, 저장되는 텀의 수가 기하급수적으로 커지기 때문에 사용하는 것을 조심해야한다.
카테고리 목록이나 태그 목록과 같은 전체 개수가 크지 않는 데이터를 분리 저장하여 자동 완성을 구현 때는 유용하다고 한다.
Edge NGram
단어의 앞자리부터 지정한 길이까지 한자리씩 단어를 분리하여 토큰을 저장한다.
house를mix_gram: 1, max_gram: 4적용하면,h,ho,hou,hous,house로 분리된다.
Shingle
문장을 공백 기준으로 분리하고, 분리된 문장을 단어 단위로 묶어서 토큰을 저장한다.
this is my sweet house를 2 단어씩 적용하면,this is,is my,my sweet,sweet house로 분리된다.
Unique 토큰 필터
Unique 토큰 필터는 분리된 텀 중에서 중복된 텀을 제거해주는 필터이다.
"white fox, white rabbit, white bear" 문장을 텍스트 분석하면 "white" 란 단어의 텀은 중복으로 3개가 생성된다.
Unique 토큰 필터를 사용하면, "white" 란 텀은 1개만 저장된다.
Stemming 형태소 분석
입력되는 데이터에 대해 영어의 ~s, ~ness, ~ing, ~ed 와 같은 문법적인 단어 변형에 대해 분석하고,
어간을 추출하여 기본 형태의 단어로 만들어주는 과정을 어간 추출 또는 Stemming 형태소 분석 이라고 한다.
Stemming 형태소 분석을 해주는 역할은 Stemmer 형태소 분석기라고 하는데, Elasticsearch 에서는
이런 Stemmer 형태소 분석기도 플러그인 형태로도 많이 지원하고 있다고 한다.
Snowball
Snowball 형태소 분석기는 2000년부터 가장 많이 활용되고 있는 형태소 분석기이며, ~ing, ~s 등을 제거여 문장의 단어들을 기본 형태로 변환해준다.
Snowball 은 애널라이저, 토크나이저, 토큰 필터가 모두 정의되어 있다.
Nori
Nori 형태소 분석기는 형태의 변형이 어려운 한글을 위해 Elastic 사에서 6.6버전 이상부터 공식적으로 지원하는 형태소 분석기다.
기존 Elasticsearch 가 한글 공식 지원하기 전에는 아래와 같은 3가지 형태소 분석기가 한글을 담당하고 있었다.
- 아리랑 (arirang)
- 한글 애널라이저
- 은전한닢 (seunjeon)
mecab-ko-dic기반의JVM한국어 형태소 분석기- 복합명사 분해와 활용어 원형 찾기 가능
Java&Scala지원
- Open Koran Text
Scala기반 오픈소스 한국어 처리기- 텍스트 정규화, 형태소 분석 지원
Nori 형태소 분석기는 기존 은전한닢 분석기에서 mecab-ko-dic 사전을 재가공하여 구현되었다.
Nori 형태소 분석기는 먼저 설치를 하고 사용해야하기 때문에,
자세한 사용 방법은 김종민님의 가이드북을 참고하는 것이 더 좋을 것 같다.
Part.1 에서는 애널라이저가 구성되는 Character Filter 캐릭터 필터, Tokenizer 토크나이저, Token Filter 토큰 필터에 대해 알아보았고, 간단한 동작과 설정 방식에 대해 학습하였다.
Part.2 에서는 텍스트 분석을 위해 설정된 애널라이저 의 구성 또는 동작을 확인하기 위한 방법들에 대해 알아볼 차례다.
출처
- 김종민님 - Elastic 가이드북
Elastic회사의 개발자이셨던 김종민님의Elastic 가이드북을 주로 참고하여 문서 작성 계획
- Elasticsearch in Action
{kind=link}